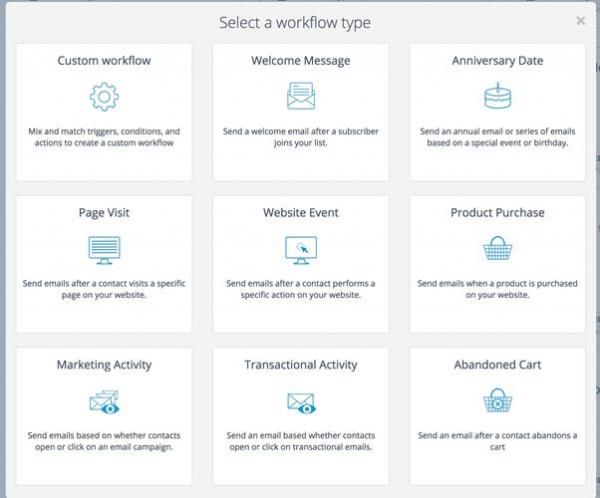
网络爬虫的数据采集方法有哪些?
API数据采集:API(应用程序接口)是软件系统之间进行通信的一种方式。通过调用特定API的数据接口,可以轻松地从各种服务中获取数据,如电商、金融、天气、地图等。 数据库数据采集:数据库是存储和管理大量数据的系统。
插图")
从网站抓取数据有多种方法,以下是三种最佳方法: 使用API接口:许多网站提供API接口,允许开发者通过API获取网站上的数据。使用API接口可以直接从网站的数据库中获取数据,速度快且准确。
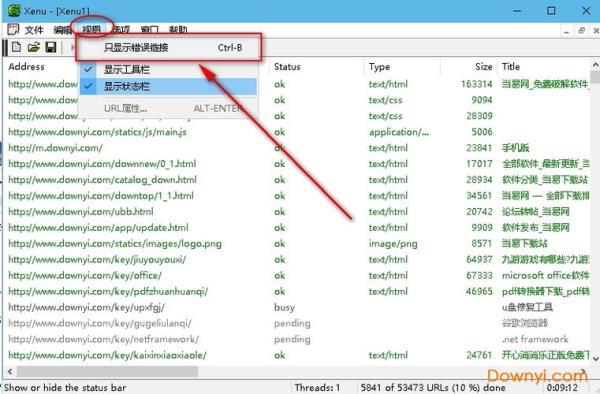
数据采集是数据处理工作的前提和基础,自动采集数据的方法通常有以下几种: 使用网络爬虫工具:网络爬虫是一种自动化程序,可以模拟人的行为,通过访问网页并提取其中的数据。
数据采集有多种方法,其中一种常用的方法是使用网络爬虫工具进行数据采集。八爪鱼采集器是一款功能全面、操作简单的网络爬虫工具,可以帮助用户快速采集网页上的数据。
互联网采集数据有以下几种常见的方法: 手动复制粘贴:通过手动复制网页上的数据,然后粘贴到本地文件或数据库中。 编写爬虫程序:使用编程语言编写爬虫程序,模拟人类在浏览器中访问网页的行为,自动抓取网页上的数据。
还在找api提取?
登录蒲公英网站,进入“应用管理”页面。找到需要提取API的应用,点击“查看详情”。在应用详情页面中,找到“API”选项卡,点击进入。在API页面中,可以看到该应用的API地址、APIKey和APISecret等信息。
找到影视仓电视盒子的API文档,了解接口的调用方法和参数。使用抓包工具(如Fiddler等)分析影视仓电视盒子的网络请求,找到具体的API接口地址。
获取接口地址发送短信API接口在开源代码里面可以查到,可以直接到开源网站查询即可。分析参数短息接口跟其他接口有所不同,短信接口是由各地运营商收费才能开通。
从网站抓取数据有多种方法,以下是三种最佳方法: 使用API接口:许多网站提供API接口,允许开发者通过API获取网站上的数据。使用API接口可以直接从网站的数据库中获取数据,速度快且准确。
使用爬虫技术中,有什么限制,意思是爬虫可以从所有的网络网站网页,企业...
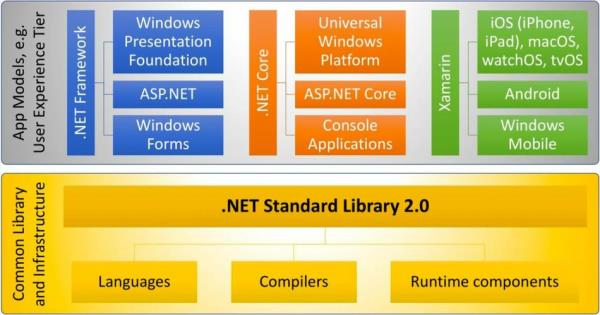
1、网络爬虫技术是一种自动化获取互联网信息的技术。它通过程序模拟人类在互联网上的浏览行为,自动访问网页并提取所需的信息。网络爬虫技术可以用于各种应用场景,如搜索引擎、数据挖掘、信息监控等。
2、爬虫通常是指网络爬虫,是一种按照一定的规则和策略,自动地抓取万维网信息的程序或者脚本。爬虫通常是指网络爬虫(Web Crawler),是一种按照一定的规则和策略,自动地抓取万维网信息的程序或者脚本。
3、网络爬虫(又称为网页蜘蛛,网络机器人,在FOAF社区中间,更经常的称为网页追逐者),是一种按照一定的规则,自动地抓取万维网信息的程序或者脚本。另外一些不常使用的名字还有蚂蚁、自动索引、模拟程序或者蠕虫。
4、网络爬虫(又被称为网页蜘蛛,网络机器人)就是模拟浏览器发送网络请求,接收请求响应,一种按照一定的规则,自动地抓取互联网信息的程序。原则上,只要是浏览器(客户端)能做的事情,爬虫都能够做。
以上就是爬虫技术抓取网站数据(爬虫抓取网页的详细流程)的内容,你可能还会喜欢爬虫技术抓取网站数据,开源网站,网页,网站查询等相关信息。